The aptly-named Journal of Craptology (est. 1998) has just published a special Valentine Day issue. It contains a silly piece on Romantic Cryptography that we originally discussed in 1999 in our Friday meetings.
Category Archives: Security engineering
New attacks on HMQV
Many people may still remember the debates a few years ago about the HMQV protocol, a modification of MQV with the primary aim of provable security. Various attacks were later discovered for the original HMQV. In the subsequent submission to the IEEE P1363 standards, the HMQV protocol has been revised to address the reported weaknesses.
However, the revised HMQV protocol is still vulnerable. In a paper that I presented at Financial Cryptography ’10, I described two new attacks. The first presents a counterexample to invalidate the basic authentication feature in the protocol. The second is generally applicable to other key exchange protocols, despite that many have formal security proofs.
The first attack is particularly concerning since the formal security proofs failed to detect this basic flaw. The HMQV protocol explicitly specifies that the Certificate Authority (CA) does not need to validate the public key except checking it is not zero. (This is one reason why HMQV claims to be more efficient than MQV). So, the protocol allows the CA to certify a small subgroup element as the user’s “public key”. Then, anyone who knows this “public key” can successfully pass authentication using HMQV (see the paper for details). Note, in this case, a private key doesn’t exit, but the authentication is successful. What is the “authentication” in HMQV based on?
The HMQV author acknowledges this attack, but states it has no bad effects. Although I disagree, this will be up to the reader to decide.
Updates:
Multichannel protocols against relay attacks
Until now it was widely believed that the only defense against relay attacks was distance bounding. In a paper presented today at Financial Cryptography 2010 we introduce a conceptually new approach for detecting and preventing relay attacks, using multichannel protocols.
We have been working on multichannel protocols since 2005. Different channels have different advantages and disadvantages and therefore one may build a better security protocol by combining different channels for different messages in the protocol trace. (For example a radio channel like Bluetooth has high bandwidth, low latency and good usability but leaves you in doubt as to whether the message really came from the announced sender; whereas a visual channel in which you acquire a barcode with a scanner or camera has low bandwidth and poorer usability but gives stronger assurance about where the message came from.)
In this new paper we apply the multichannel paradigm to the problem of countering relay attacks. We introduce a family of protocols in which at least one message is sent over a special “unrelayable” channel. The core idea is that one channel connects the verifier to the principal with whom she shares the prearranged secret K, while another channel (the unrelayable one) connects her to the prover who is actually in front of her; and the men in the middle, however much they relay, can’t get it right on both of these channels simultaneously.
We convey this idea with several stories. Don’t take them too literally but they let us illustrate and discuss all the key security points.
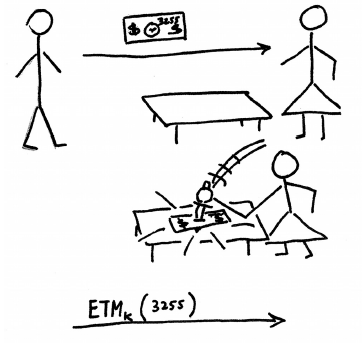
This work is exciting for us because it opens up a new field. We look forward to other researchers following it up with implementations of unrelayable channels and with formal tools for the analysis of such protocols.
Frank Stajano, Ford-Long Wong, Bruce Christianson. Multichannel protocols to prevent relay attacks (preliminary; the final revised version of the full paper will be published in Springer LNCS)
Placebo bomb detectors
A few days ago, BBC2’s Newsnight approached me to have a look inside what might have been some kind of smartcard, but had long been suspected to be part of a simple-minded and dangerous fraud that may already have cost lives. Continue reading Placebo bomb detectors
Encoding integers in the EMV protocol
On the 1st of January 2010, many German bank customers found that their banking smart cards had stopped working. Details of why are still unclear, but indications are that the cards believed that the date was 2016, rather than 2010, and so refused to process a transaction supposedly after their expiry dates. This problem could turn out to be quite expensive for the cards’ manufacturer, Gemalto: their shares dropped almost 4%, and they have booked a €10 m charge to handle the consequences.
These cards implement the EMV protocol (the same one used for Chip and PIN in the UK). Here, the card is sent the current date in 3-byte YYMMDD binary-coded decimal (BCD) format, i.e. “100101” on 1 January 2010. If however this was interpreted as hexadecimal, then the card will think the year is 2016 (in hexadecimal, 1 January 2010 should have actually been “0a0101”). Since the numbers 0–9 are the same in both BCD and hexadecimal, we can see why this problem only occurred in 2010*.
In one sense, this looks like a foolish error, and should have been caught in testing. However, before criticizing too harshly, one should remember that EMV is almost impossible to implement perfectly. I have written a fairly complete implementation of the protocol and frequently find edge cases which are insufficiently documented, making dealing with them error-prone. Not only is the specification vague, but it is also long — the first public version in 1996 was 201 pages, and it grew to 765 pages by 2008. Moreover, much of the complexity is unnecessary. In this article I will give just one example of this — the fact that there are nine different ways to encode integers.
Mobile Internet access data retention (not!)
In the first article in this series I discussed why massive use of Network Address Translation (NAT) means that traceability for mobile Internet access requires the use of source port numbers. In the second article I explained how in practice the NAT logging records, that record the mapping from IP address to customer, are available for only a short time — or may not exist at all.
This might seem a little surprising because within the EU a “data retention” regime has been in place since the Spring of 2009. So surely the mobile phone companies have to keep the NAT records of Internet access, even though this will be horribly expensive?
They don’t!
The reason is that instead of the EU Directive (and hence UK and other European laws) saying what was to be achieved — “we want traceability to work” — the bureaucrats decided to say what they wanted done — “we want logs of IP address allocation to be kept”. For most ISPs the two requirements are equivalent. For the mobile companies, with their massive use of NAT, they are not equivalent at all.
The EU Directive (Article 5) requires an ISP to retain for all Internet access events (the mobile call itself will require other info to be retained):
(a)(i) the user ID(s) allocated;
(a)(iii) the name and address of the subscriber or registered user to whom an Internet Protocol (IP) address, user ID or telephone number was allocated at the time of the communication;
(c)(i) the date and time of the log-in and log-off of the Internet access service, based on a certain time zone, together with the IP address, whether dynamic or static, allocated by the Internet access service provider to a communication, and the user ID of the subscriber or registered user;
(e)(ii) the digital subscriber line (DSL) or other end point of the originator of the communication;
That is, the company must record which IP address was given to the user, but there is no requirement to record the source port number. As discussed in this series of articles, this makes traceability extremely problematic.
It’s also somewhat unclear (but then much more of the Directive is technically unclear) whether recording the “internal” IP address allocated to the user is sufficient, or whether the NAT records (without the port numbers) need to be kept as well. Fortunately, in the UK, the Regulations that implement the Directive make it clear that the rules only apply once a notice has been served on an ISP, and that notice must say to what extent the rules apply. So in principle, all should be clear to the mobile telcos!
By the way … this bureaucratic insistence on saying what is to be done, rather than what is to be achieved, can also be found in the Digital Economy Bill which is currently before the House of Lords. It keeps on mentioning “IP addresses” being required, with no mention of source port numbers.
But perhaps that particular problem will turn out OK? Apple will not let anyone with an iPhone download music without permission!
Practical mobile Internet access traceability
In an earlier article I explained how the mobile phone companies are using Network Address Translation on a massive scale to allow hundreds of Internet access customers to share a single IP address. I pointed out how it was now necessary to record the source port as well as the IP address if you wanted to track somebody down.
Having talked in detail about this with one of the UK’s major mobile phone companies, I can now further describe some practical issues (Caveat: other companies may differ in how they’ve implemented their details, but all of them are doing something very similar).
The good news, first, is that things are not as bad as they might be!
By design, NAT systems provide a constant mapping to a single IP address for any given user (at least until they next disconnect). This means that, for example, a website that is tracking visitors by IP address will not serve the wrong content; and their log analysis program will see constant IP addresses when the user changes page or fetches an image, so that audience measurements will remain valid. From a security point of view, it means that provided you have at least one logging record with IP address + port number + timestamp, then you will have sufficient data to be able to seek to make an identification.
As a quick aside, you may be thinking that you could do an “inference attack” to identify someone without using a source port number. Suppose that you can link several bad events together over a period of time, but only have the IP address of each. Despite the telco having several hundred people using each IP address at each relevant instant, only one user might be implicated on every occasion. Viewers of the wire will recall a similar scheme being used to identify Stringer Bell’s second SIM card number!
Although this inference approach would work fine in theory, the telco I spoke with does not keep its records in a suitable form for this to be at all efficient. So, even supposing that one could draft the appropriate legal request (a s22 notice, as prescribed by the UK’s Regulation of Investigatory Powers Act), the cost of doing the searches and collating the results (and those costs are borne by the investigators), would be prohibitive.
But now it’s time for the bad news.
Traditional ISP IP address usage records (in RADIUS or similar systems) have both a “start” and “stop” record. The consistency of these records within the logging system gives considerable assurance that the data is valid and complete. The NAT logging only records an event when the source port starts to be used — so if records go missing (and classical syslog systems can lose records when network errors occur), then there is no consistency check to show that the wrong account has been identified.
The logging records that show which customer was using which IP address (and source port) are extremely large — dozens of records can be generated by viewing just one web page. They also provide sensitive information about customer habits, and so if they are retained at all, it will only be for a short period of time. This means that if you want traceability then you need to get a move on. ISPs typically keep logs of IP address usage for a few weeks. At the mobile companies (because of the volume) you will in practice have to consult the records within just a few days.
Furthermore, even when the company intends to hold the data for a short period, it turns out that under heavy load the NAT equipment struggles to do what it’s supposed to be doing, leave alone generate gigabytes of logging. So the logging is often turned off for long periods for service protection reasons.
Clearly there’s a reputational risk to not having any records at all. For an example which does not have anything to do with policing: not being able to track down the sources of email spam would demean the mobile company in the eyes of other ISPs (which in practice will be seen by ever more aggressive filtering of all of their email). However, that risk is rather long-term; keeping the system running “now” is rather more important; and there is a lot that a mobile company can do to block and detect spam within their own networks — they don’t need to rely on being able to process external abuse reports.
In the third and final article of this little series I will consider the question of “data retention”. Surely the mobile phone company has a legal duty to keep traceability records? It turns out that the regulators screwed it up — and they don’t!
Extending the requirements for traceability
A large chunk of my 2005 PhD thesis explained how “traceability” works; how we can attempt to establish “who did that?” on the Internet.
The basics are that you record an IP address and a timestamp; use the Regional Internet Registry records (RIPE, ARIN etc) to determine which ISP has been allocated the IP address; and then ask the ISP to use their internal records to determine which customer account was allocated the IP address at the relevant instant. All very simple in concept, but hung about — as the thesis explained — by considerable caveats as to whether the simple assumptions involved are actually true in a particular case.
One of the caveats concerned the use of Network Address Translation (NAT), whereby the IP addresses used by internal machines are mapped back and forth to external IP addresses that are visible on the global Internet. The most familiar NAT arrangement is that used by a great many home broadband users, who have one externally facing IP address, yet run multiple machines within the household.
Companies also use NAT. If they own sufficient IP addresses they may map one-to-one between internal and external addresses (usually for security reasons), or they may only have 4 or 8 external IP addresses, and will use some or all of them in parallel for dozens of internal machines.
Where NAT is in use, as my thesis explained, traceability becomes problematic because it is rare for the NAT equipment to generate logs to record the internal/external mapping, and even rarer for those logs to be preserved for any length of time. Without these logs, it is impossible to work out which internal user was responsible for the event being traced. However, in practice, all is not lost because law enforcement is usually able to use other clues to tell them which member of the household, or which employee, they wish to interview first.
Treating NAT with this degree of equanimity is no longer possible, and that’s because of the way in which the mobile telephone companies are providing Internet access.
The shortage of IPv4 addresses has meant that the mobile telcos have not been able to obtain huge blocks of address space to dish out one IP address per connected customer — the way in which ISPs have always worked. Instead, they are using relatively small address blocks and a NAT system, so that the same IP address is being simultaneously used by a large number of customers; often hundreds at a time.
This means that the only way in which they can offer a traceability service is if they are provided with an IP address and a timestamp AND ALSO with the TCP (or UDP) source port number. Without that source port value, the mobile firm can only narrow down the account being used to the extent that it must be one out of several hundred — and since those several hundred will have nothing in common, apart from their choice of phone company, law enforcement (or anyone else who cares) will be unable to go much further.
So, the lesson here is clear — if you are creating logs of activity for security purposes — because you might want to use the information to track someone down — then you must record not only the IP address, but also the source port number.
This will soon be a necessity not just for connections from mobile companies, but for many other Internet access providers as well — because of the expected rise of “Carrier Grade NAT” (or “Large Scale NAT“), as one way of staving off the advent of the different sort of world we will enter when we “run out” of IPv4 addresses — sometime in the next two or three years.
There is currently an “Internet Draft” (a document that might become an RFC one day) that sets out a number of other issues which arise when addresses are routinely shared … though the authors appear unaware that this isn’t something to worry about in 2011, but something that has already been happening for some time, and at considerable “scale”.
In my next article, I’ll discuss what this massive use of NAT means in practice when traceability leads you to a mobile phone user.
How to vote anonymously under ubiquitous surveillance
In 2006, the Chancellor proposed to invade an enemy planet, but his motion was anonymously vetoed. Three years on, he still cannot find out who did it.
This time, the Chancellor is seeking re-election in the Galactic Senate. Some delegates don’t want to vote for him, but worry about his revenge. How to arrange an election such that the voter’s privacy will be best protected?
The environment is extremely adverse. Surveillance is everywhere. Anything you say will be recorded and traceable to you. All communication is essentially public. In addition, you have no one to trust but yourself.
It may seem mind-boggling that this problem is solvable in the first place. With cryptography, anything is possible. In a forthcoming paper to be published by IET Information Security, we (joint work with Peter Ryan and Piotr Zielinski) described a decentralized voting protocol called “Open Vote Network”.
In the Open Vote Network protocol, all communication data is open, and publicly verifiable. The protocol provides the maximum protection of the voter’s privacy; only a full collusion can break the privacy. In addition, the protocol is exceptionally efficient. It compares favorably to past solutions in terms of the round efficiency, computation load and bandwidth usage, and has been close to the best possible in each of these aspects.
With the same security properties, it seems unlikely to have a decentralized voting scheme that is significantly more efficient than ours. However, in cryptography, nothing is ever optimal, so we keep this question open.
A preprint of the paper is available here, and the slides here.
The Real Hustle and the psychology of scam victims
This, which started as a contribution to Ross’s Security and Psychology initiative, is probably my most entertaining piece of research this year and it’s certainly getting its bit of attention.
I’ve been a great fan of The Real Hustle since 2006, which I recommend to anyone with an interest in security, and it has been good fun to work with the TV show’s coauthor Paul Wilson on this paper. We analyze the scams reproduced in the show, we extract general principles from them that describe typical behavioural patterns exploited by hustlers and then we show how an awareness of these principles can also strengthen systems security.
In a few months I have given versions of this talk around the world: Boston, London, Athens, London, Cambridge, Munich—to the security and psychology crowd, to computer researchers, to professional programmers—and it never failed to attract interest. This is what Yahoo’s Chris Heilmann wrote in his blog when I gave the talk at StackOverflow to an audience of 250 programmers:
The other talk I was able to attend was Frank Stajano, a resident lecturer and security expert (and mighty sword-bearer). His talk revolved around application security but instead of doing the classic “prevent yourself from XSS/SQL injection/CSRF” spiel, Frank took a different route. BBC TV in the UK has a program called The Real Hustle which shows how people are scammed by tricksters and gamblers and the psychology behind these successful scams. Despite the abysmal Guy Ritchie style presentation of the show, it is full of great information: Frank and a colleague conducted a detailed research and analysis of all the attacks and the reasons why they work. The paper on the research is available: Seven principles for systems security (PDF). A thoroughly entertaining and fascinating presentation and a great example of how security can be explained without sounding condescending or drowning the audience in jargon. I really hope that there is a recording of the talk.
I´m giving the talk again at the Computer Laboratory on Tuesday 17 November in the Security Seminars series. The full write-up is available for download as a tech report.